
Only a few weeks after launching a major overhaul of its Cloud Text-to-Speech API, Google today also announced an update to that service’s Speech-to-Text voice recognition service. The new and improved Cloud Speech-to-Text API promises significantly improved voice recognition performance. The new API promises a reduction in word errors around 54 percent across all of Google’s tests, but in some areas the results are actually far better than that.
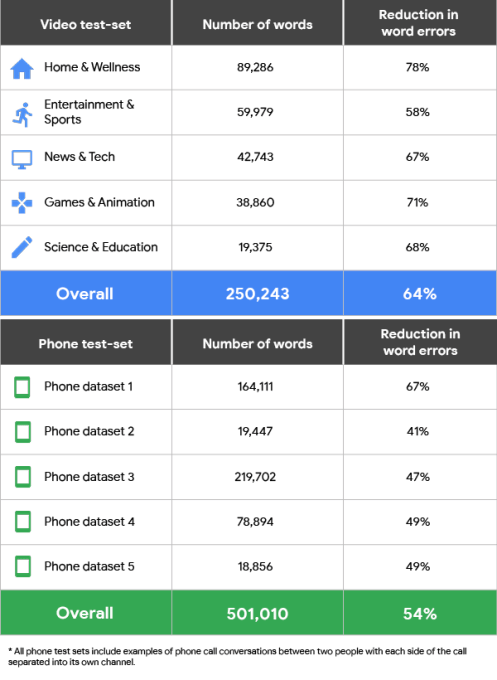 Part of this improvement is a major new feature in the Speech-to-Text API that now allows developers to select between different machine learning models based on this use case. The new API currently offers four of these models. There is one for short queries and voice commands, for example, as well as one for understanding audio from phone calls and another one for handling audio from videos. The fourth model is the new default, which Google recommends for all other scenarios.
Part of this improvement is a major new feature in the Speech-to-Text API that now allows developers to select between different machine learning models based on this use case. The new API currently offers four of these models. There is one for short queries and voice commands, for example, as well as one for understanding audio from phone calls and another one for handling audio from videos. The fourth model is the new default, which Google recommends for all other scenarios.
In addition to these new speech recognition models, Google is also updating the service with a new punctuation model. As the Google team admits, its transcriptions have long suffered from rather unorthodox punctuation. Punctuating transcribed speech is notoriously hard though (just ask anybody who has ever tried to transcribe a speech by the current U.S. president…). Google promises that its new model results in far more readable transcriptions that feature fewer run-on sentences and more commas, periods and questions marks.
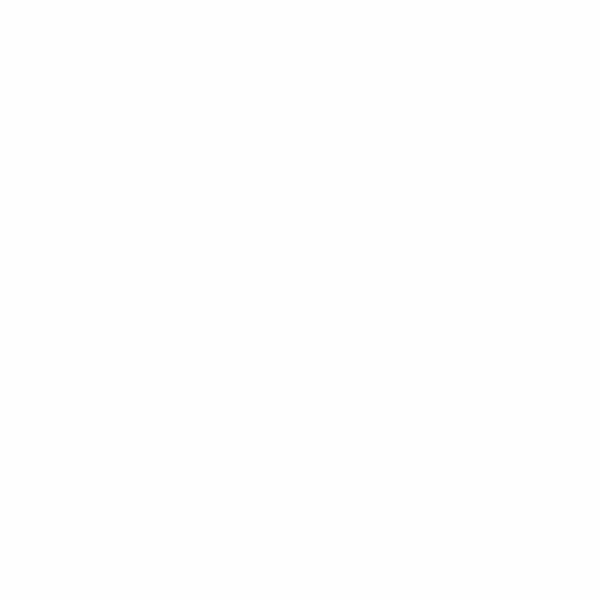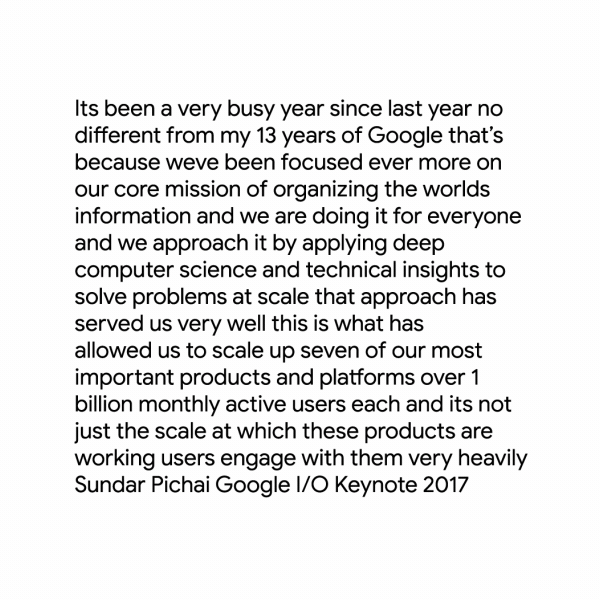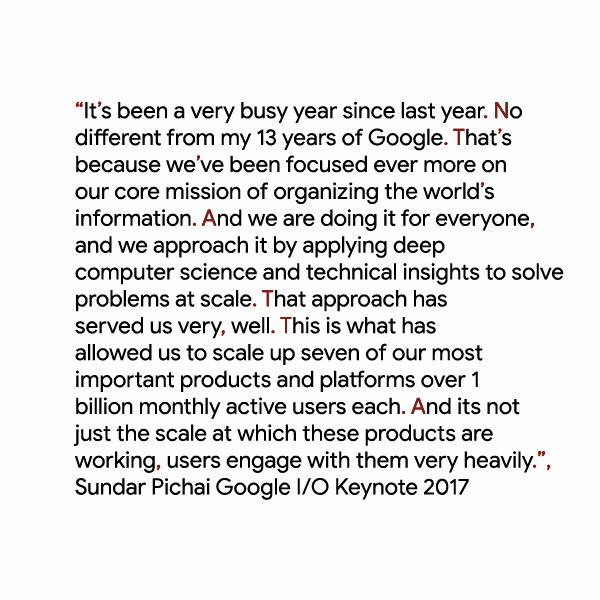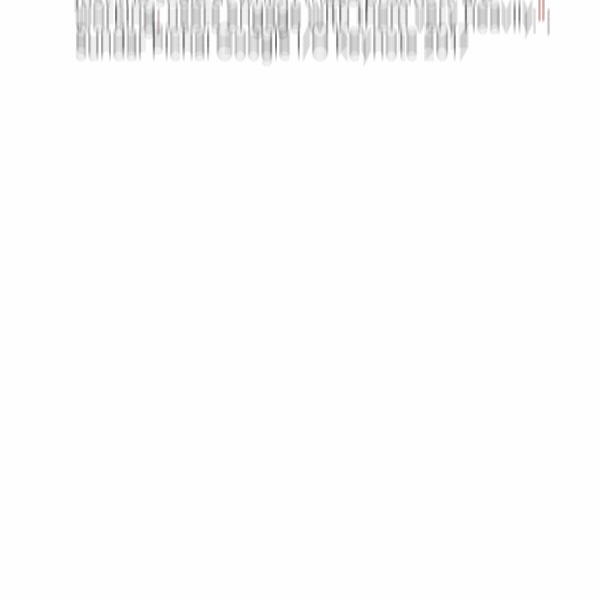
With this update, Google now also lets developers tag their transcribed audio or video some basic metadata. There is no immediate benefit to the developer here, but Google says that it will use the aggregate information from all of its users to decide on which new features to prioritize next.
Google isn’t making a small change to how it charges for this service. Like before, audio transcripts cost $0.006 per 15 seconds. The video model will cost twice as much, though, at $0.012 per 15 seconds, though until May 31, using this new model will also cost $0.006 per 15 seconds, too.
