




If you’re worried about someone finding out what you’re pointing your browser at, there are plenty of options for keeping it secret, with varying levels of difficulty and effectiveness. Veil takes things further than perhaps any other anonymous browsing method by masking the page you’re viewing not just from would-be attackers, but from your own operating system.
The problem, as the MIT researchers behind Veil explain in a new paper outlining the service, is that private browsing modes, even ones using Tor and other measures, can still leave a trace of your history on the device itself, in RAM or temporary storage.
When you visit a page, even anonymously, that page and its components still have to be loaded into memory, displayed and cached, libraries or plugins perhaps accessed or modified. The browser may try to delete these traces, but success can vary depending on how things are set up. A sort of ghost version of your activity may live on in your RAM, even if it’s just a hash of some data or timestamp.
“The fundamental problem is that [the browser] collects this information, and then the browser does its best effort to fix it. But at the end of the day, no matter what the browser’s best effort is, it still collects it,” explained MIT graduate student Frank Wang, the lead author of the paper, in a news release. “We might as well not collect that information in the first place.”
Veil takes things several steps further by handling delivery of the site via what they call a “blinding server.” You enter the URL into the site and the page is retrieved for you from the special servers, encrypted it in transit and in your browser cache, and only decrypted for your viewing. Links and URLs are themselves encrypted so they can’t be linked to the content requested.
Furthermore, it injects invisible garbage code into the page while also “mutating” the content (again, invisibly) so that you could load it a thousand times on the same computer and although it would look the same to you, any resulting digital fingerprints like hash, payload size, and so on would always be different.
This way your computer never actually registers the actual URL, never caches any of the data, and any traces left won’t match up with any database or even each other.
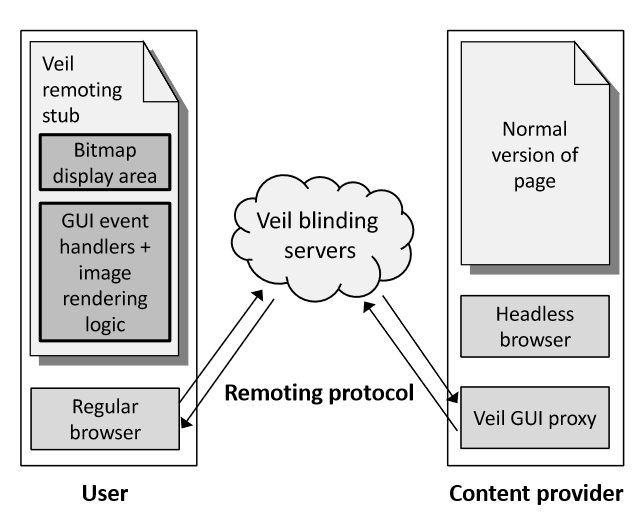
In the most extreme privacy case, users don’t even interact with the actual webpage — just an image of it.
Converting webpages to Veil-compatible ones can be done via a special compiler provided by the researchers. It shouldn’t break anything, though it will add to the bandwidth used and requests served, owing to the mutations and extra crypto operations.
But wait, there’s more! For those of you worried that even that level of obfuscation isn’t enough, there’s an option that I’ve always considered a possibility but never seen executed: browsing via visual data alone.
If you want, Veil will instead of showing you the target site’s actual code, just take a screenshot and show you that. You can click on the screenshot and it will record the location of that click, then transmit it to the actual page, returning a screenshot of the result.
The next step, I suppose, will be to employ a robot that looks at a completely separate computer somewhere and tells you what it sees in piglatin. Onnection-cay ecure-say!
Of course this isn’t a zero-trust situation: the blinding servers will, like Tor nodes, be run by volunteers and organizations that could attempt to compromise the system (a site could also run its own). But if the process is mathematically and procedurally verifiable, you should be okay. Of course security researchers will want to audit the code.
Veil was presented this week at the Network and Distributed Systems Security Symposium in San Diego. You can read the full paper here.
Featured Image: Yuri Samoilov/Flickr UNDER A CCPL LICENSE (IMAGE HAS BEEN MODIFIED)
